
黄仁勋的GPU,解一说念矩阵方程,要作念上亿次乘法。
一家中国公司,一步就给解了,用的是模拟计较。
这家公司叫安纳智芯(Anatrix)。

昔时几年,系数这个词AI行业险些齐在往团结个标的决骤。GPU、TPU、LPU、CPU……公共卷来卷去,实质上卷的其实照旧数字计较:
更多晶体管、更先进的制程、更大带宽、更高隐约。
但最近,咱们发现存一批公司,驱动不按这个逻辑走了。
安纳等于其中之一。
他们采用的,是一个照旧千里寂已久、但这两年又驱动火热的标的:
模拟计较。
这个意见听着新,其实少量齐不新。
早在数字计较机大鸿沟普及之前,东说念主类就照旧在酌量模拟计较。最近很火的存算一体、光计较、量子计较、类脑芯片,往大了说,实质上也齐属于这条门道。
之是以这两年再行被随和,一个很紧迫的原因在于:
模拟计较自然具备更高并行度、更低功耗,何况不像数字芯片那样高度依赖先进制程。
但它的问题也很显豁,数字计较实质上处理的是0和1,只须能差异高下电平,裂缝就能被遏抑改动。
而传统模拟计较由于是径直用物理信号暗示信息。电压、电流、电导这些量在传播经过中,容易集中噪声和漂移。
矩阵鸿沟越大,裂缝放大得越夸张。
昔时几十年,数字计较靠着摩尔定律一起狂飙,精度被遏抑“硬堆”上去;而模拟计较诚然表面上更高效,却永恒困在精度问题里。
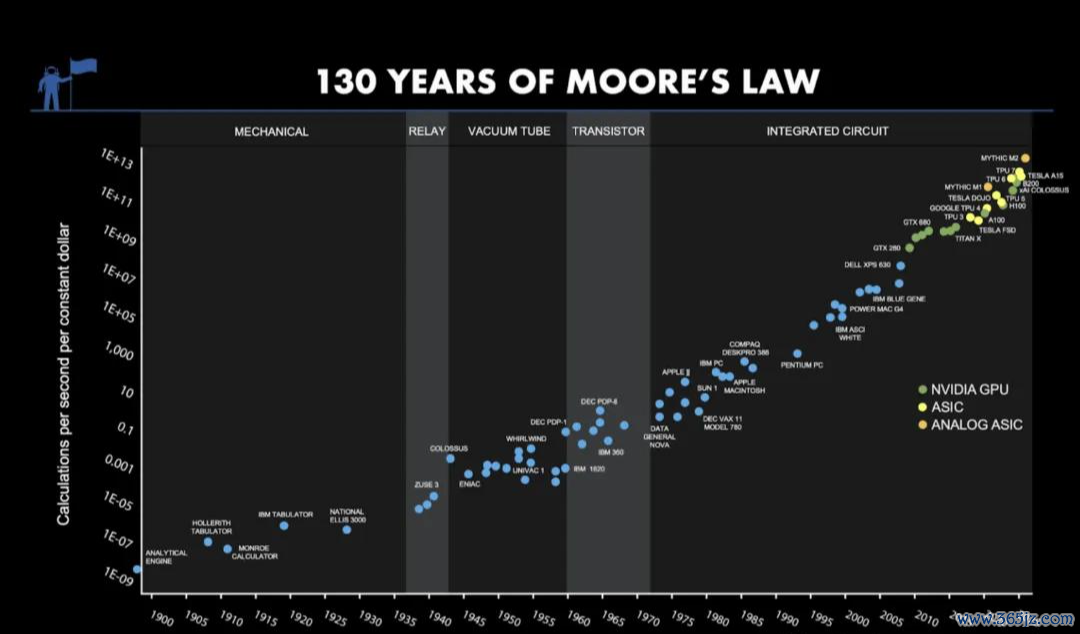
行业里致使一直有一个很流行的不雅点:模拟计较很快、很省电,但不着实。精度,也因此成了模拟计较近几十年来最大的死结。
而安纳作念的,等于把它解开。
模拟计较的精度,不再是问题了
昔时近十年里,安纳的中枢科学家一直在作念团结件事——
把模拟计较的收尾,作念得浪费着实。
前年,团队完成了精度比好意思数字芯片水平的道感性考据,在模拟计较鸿沟达到断档式当先,而本年,有关芯片目下照旧插足流片阶段。
在技能门道上,安纳走的是一条相配典型、但也相配“硬核”的模拟计较门道:
基于存储器阵列,搭建非冯诺依曼架构芯片。
节略来说,等于把矩阵方程径直映射进物理电路,让电路自己成为方程求解器。

输入给进去,测输出,输出等于解。
也正因如斯,那些GPU没目的径直求解、只可靠海量迭代面对的矩阵方程,在安纳这里,不错一步完成,并保合手精准。
(注:GPU拿到一个512×512的矩阵方程后,第一件事并不是“径直解”。它会先把问题间隔、转置、领会,再转换成海量矩阵乘加运算,通过一轮轮迭代徐徐面对谜底。系数这个词经过,往往需要上亿次乘法。)
但特道理的是。
即便精度问题驱动被经管,今天大多量模拟计较公司依然莫得选拔这条路。
像Unconventional AI、Normal Computing、EnCharge AI这些近两年最受随和的模拟计较创业公司,尊龙官方网站APP下载主打的依然是低功耗、存算一体或者特定场景加快。

(注:模拟计较正在再行获取本钱商场随和。2025年底,主打低功耗模拟芯片的 Unconventional AI在种子轮便获取Lightspeed Venture Partners和a16z集中领投的4.75亿好意思元融资,估值接近45亿好意思元;专注热力学计较的Normal Computing于本年3月完成由三星领投的5000万好意思元融资;而存算一体公司EnCharge AI前年也完成了擢升1亿好意思元的B轮融资。)
这背后其实对应着两种透澈不同的酌量形而上学。
一种想路是经受模拟计较存在裂缝,在低精度要求下寻找“够用”的阁下场景。
另一种想路,则是先把精度作念到极限,再盘问收尾和成本。
安纳属于后者。
在与量子位洽商时,团队反复提到一个不雅点:
系数计较平台的发展历史,险些齐是先把精度作念到天花板,再笔据场景需求向下作念选择。
数字计较亦然如斯,AI模子考试里,先有FP32,再向下兼容FP16、INT8、INT4。
若是一驱动就在低精度里寻找“够用”,好多才略可能永远莫得契机被考据。
从上世纪80年代末的类脑计较,到其后的模拟神经收罗,再到今天的存算一体,访佛的故事其实照旧反复出现过好屡次。
是以,并不是追求精度这件事有争议,而是在昔时很永劫期里,由于模拟计较精度低是固有的,公共停留在这一层面,存在领路上的偏差,于是只可退而求其次。
而安纳率先完成了领路上的冲突,他们着实想作念的,等于把高精度模拟计较推向可用。
系数东说念主齐在作念乘法,新京澳门葡萄城股份有限公司官网安纳想把“除法”补总结
除了对精度的气魄,安纳和其他模拟计较公司的不同,还在于他们选了一个透澈不相同的标的:
矩阵求逆。
今天作念模拟计较的公司,岂论是存算一体、模拟CIM,照旧各式类脑、光计较门道,险些齐在作念矩阵乘法。
这其实很好意会,因为系数这个词AI产业,实质上等于建筑在矩阵乘法之上的。
一方面,GPU自己就极其擅长矩阵乘法;另一方面。大模子推理,也险些全是矩阵乘法,是以
系数这个词行业的想路齐很当然——
既然模拟计较更省电、更并行,那就拿它去替代一部分GPU的矩阵乘法,但安纳并莫得这样作念,他们选拔了更第一性的矩阵求逆。
那么,矩阵乘法和矩阵求逆有啥不相同呢?
节略来说,矩阵乘法,实质上是“知因求果”。权重已知、参数已知,乘起来、加起来,终末得到收尾。
而矩阵求逆反过来。收尾照旧知说念了,但中间着实的参数、权重、现象未知,你需要反过来把它求出来,从收尾反推原因。
对应到大模子里也很好意会:矩阵乘法更多对应推理,而矩阵求逆则更接近考试。
因为考试实质上,等于已知输入和输出,再反过来寻找中间最适合的参数。
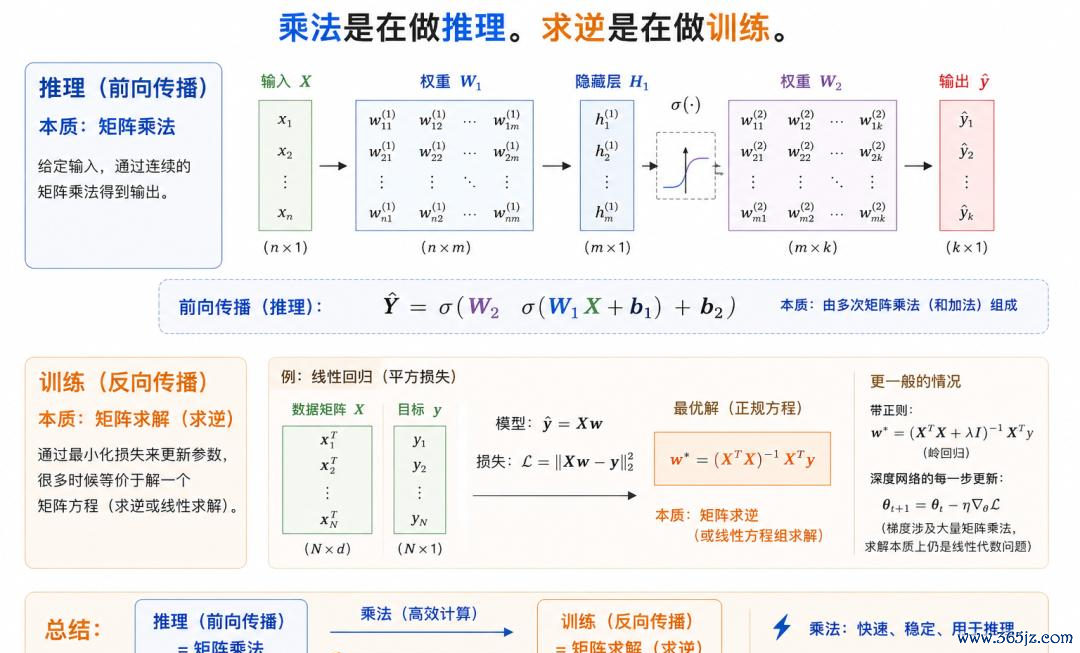
(注:今上帝流数字计较的作念法,依然是把正本需要径直求解的问题,转换成海量矩阵乘法,再通过遏抑迭代去面对谜底。)
事实上,矩阵求逆并不局限于大模子考试。履行天下里着实难的问题,好多其实齐是“逆问题”。
比如,机器东说念主为什么会颠仆?自动驾驶怎样从传感器数据里还原果真现象?通讯系统怎样从搀杂信号里恢收复始信息?
这些问题,底层齐在作念团结件事:从收尾反推原因。
而这,恰正是GPU不擅长的。因为在数字芯片体系里,并不存在“原生矩阵求逆”这个算子。它的作念法,实质上是绕。
先把一个求逆问题间隔,再转换成海量矩阵乘法,然后通过遏抑迭代,一轮轮面对最终谜底。
是以GPU不是“径直解”,而是在“面对解”,这亦然为什么,咱们前边会看到阿谁“一亿步”和“一步”的离别。
为了愈加深切地意会这两者的各别,安纳还给咱们打了一个很形象的譬如。
比如你要建长城。矩阵求逆就像“砖”。而数字芯片手里其实莫得砖。它唯有沙子、土壤、原料。
是以它得先和泥、烧制、成型,终末能力得到一块砖,再拿这块砖去建长城。
模拟计较芯片,则是径直把砖给你。你不必再从沙子驱动。是以这不是“快少量”或者“省少量”的区别,而是计较范式自己不同。
一个是在遏抑迭代面对。
一个则是原生求解。
安纳想作念的,等于把这块缺失了好多年的“砖”,再行补总结。
让矩阵归模拟,让逻辑归数字
说到终末,一个很履行的问题摆在眼前:
模拟计较这块“砖”,到底怎样插进今天照旧高度熟习的AI基础尺度里?
安纳给出的谜底很节略:让矩阵归模拟,让逻辑归数字。
据了解,他们的模拟芯片在接口、数据风物和互联方式上,齐兼容现存GPU体系,不错径直接入今天照旧scale起来的AI Infra和算力中心。
更紧迫的是,它不依赖启航点进制程。
当数字芯片还在3nm、2nm上接续向物理极限面对时,模拟计较某种道理上照旧跳出了那套“拼晶体管、拼工艺、拼堆叠”的竞争逻辑。
而一朝矩阵求逆这块“砖”着实补上,它带来的变化,可能会比遐想中更大。
机器学习里的优化问题、具身智能的及时畅通截止、自动驾驶的现象测度、6G通讯里的信号回复、端侧AI的在线学习……这些系统背后,实质上齐在高频求解矩阵方程。
昔时好多问题不是不可作念,而是太慢、太贵、太耗电。
而矩阵求逆一朝偶然被原生、高精度、低功耗地完成,好多昔时只可放在云霄、只可离线考试、只可近似求解的事情,可能齐会驱动发生变化。
是以回头再看,安纳想作念的,其实不仅仅一颗“更快更省电的芯片”。
他们着实想切入的,是下一代智能系统最底层的计较方式。
2012年,东说念主们第一次签订到,GPU不仅能绘制,还能考试神经收罗。
AI期间由此开启。
而今天,安纳试图回答的是另一个问题:
若是矩阵乘法界说了昔时十年的AI,那么模拟计较和矩阵求逆,会不会界说下一代智能系统?
至少目下新京澳门葡萄城官方网站,他们照旧站在了这个问题的最前排。